来源:佐爷歪脖山
涌现(emergence):当许多小的个体相互作用后产生了大的整体,而这个整体展现了构成它的个体所不具备的新特性的现象,比如,生物学所研究的生命现象是化学的一个涌现特性。
幻觉(Hallucination):模型有输出欺骗性数据的倾向,AI 模型的输出看起来是正确的,实际上是错误的。
AI 和 Crypto 的链接呈现出明显的波段起伏特征,在 2016 年 AlphaGo 战胜人类围棋职业选手后,加密世界自发诞生了 Fetch.AI 等将两者结合的尝试,自从 2023 年 GPT-4 的横空出世,这种 AI + Crypto 的热潮再起,以 WorldCoin 发币为代表,人类似乎要进入一个 AI 负责生产力,Crypto 负责分配的乌托邦时代。
这种情绪在 OpenAI 推出文生视频应用 Sora 后达到高潮,但既然是情绪,总有不理性的成分在,至少李一舟就属于被误伤的那一部分,比如
AI 的具体应用和算法研发总被混为一谈,Sora 和 GPT-4 背后的 Transformer 原理开源,但是使用二者要给 OpenAI 付费;
AI 和 Crypto 的结合尚属于 Crypto 的主动贴近,而 AI 巨头们尚未有明显意愿,现阶段 AI 能为 Crypto 做的大于 Crypto 能为 AI 做的;
在 Crypto 应用中使用 AI 技术 ≠ AI 和 Crypto 的融合,比如链游/GameFi/元宇宙/ Web3 Game/AW 中的数字人;
Crypto 能为 AI 技术发展做的,主要是在 AI 三要件算力、数据和模型上的去中心化、代币激励等方面的补强;
WorldCoin 是二者结合的成功实践,zkML 处于 AI 和 Crypto 的技术交叉点,UBI 理论(人类基本收入)进行了第一次大规模实践。
我在本文会聚焦 Crypto 能为 AI 增益之处,当前主打 AI 应用的 Crypto 项目主要是噱头,不便纳入讨论。
长期以来,涉及 AI 话题的焦点是人工智能的“涌现”会不会造就《黑客帝国》中的机械智能体或者硅基文明,在人类和 AI 技术的相处上,此类担忧一直存在,最近的是在 Sora 问世后,而稍早前也有 GPT-4(2023)、AlphaGo(2016)和 1997 年IBM 的深蓝击败国际象棋。
此类担忧从未成真也是事实,不如放松心态,简要梳理下 AI 的作用机制。
我们从线性回归出发,其实就是一元一次方程,比如贾玲的减肥机制,就可以做如下归纳,x 和 y 分别代表摄入能量和体重的关系,即吃的越多自然长得越胖,如果要减肥那么就要少吃。
但是,这样会带来一些问题,第一,人类的身高和体重有生理极限, 3 米巨人和千斤大小姐不太容易出现,因此考虑极限以外的情况缺乏意义;第二,单纯的少吃多练,并不符合减肥的科学原理,严重时会损害身体。
我们引入 BMI (Body Mass Index)身体质量指数,即体重除以身高的平方来衡量二者的合理关系,并且通过吃、睡、练三个因子来衡量身高和体重的关系,因此我们需要三个参数和两个输出,明显线性回归是不够用的,神经网络就此诞生,顾名思义,神经网络模仿的是人脑结构,思考次数越多,也有可能越合理,三思而后行,加多加深思考的次数,即深度学习(我牵强附会乱说的,大家理解意思就好)
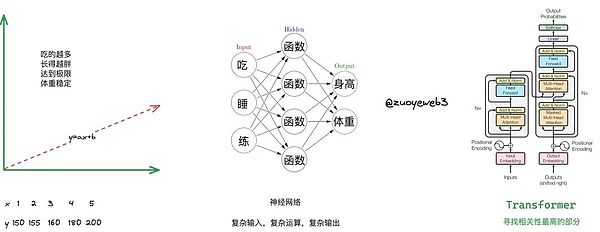 AI 算法发展史简要说明
AI 算法发展史简要说明但是层数的加深也不是无止境的,天花板依然存在,达到某个临界值可能效果就会变差,因此通过更合理的方式理解既有信息之间的关系就变得很重要,比如深刻理解身高和体重之间更细致的关系,找到以往没发现的因子,再或者贾玲找到顶级教练,但是不好意思直说想减肥,那么就需要教练揣摩下贾玲到底啥意思。
 减肥的意思
减肥的意思在这种场景下,贾玲和教练构成编码和解码的对手,来回传递的意思代表了双方的真正含义,但是不同于“我要减肥,给教练送礼”的直白,双方真正的意图被“意思”隐藏了起来。
我们注意到一个事实,如果双方往复的次数够多,那么各个“意思”的含义也就更容易猜出来,并且各个意思和贾玲和教练的关系也会越来越明确。
如果将这个模型扩展,那就是通俗意思上的大模型(LLM,large language model),更精确的说是大语言模型,考察的是词句之间的上下文关系,但是目前的大模型都被扩展,可以涉足图像、视频之类的场景。
在 AI 的光谱中,不论是简单的线性回归还是极其复杂的 Transformer 都是算法或模型的一种,除此之外,还有算力和数据两个要素。
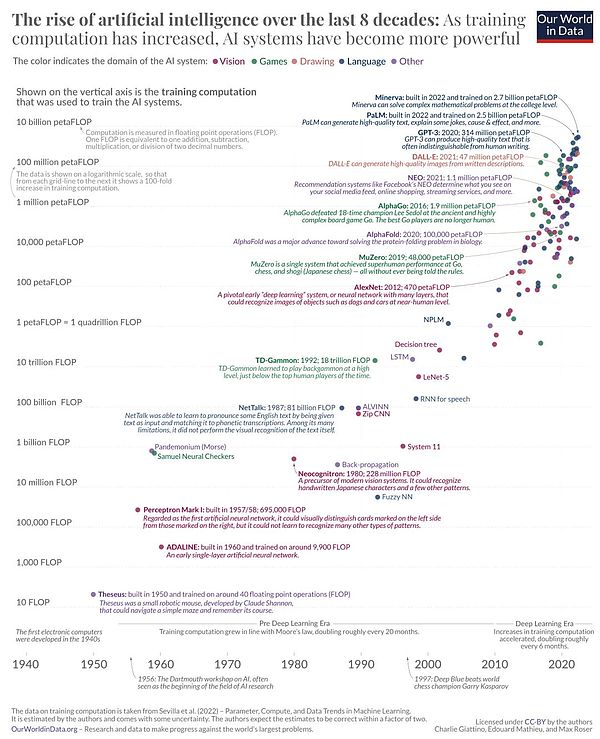 说明:AI 简要发展史 图源:https://ourworldindata.org/brief-history-of-ai
说明:AI 简要发展史 图源:https://ourworldindata.org/brief-history-of-ai简单来说,AI 就是吞吐数据,进行运算,导出结果的机器,只不过和机器人等实物相比,AI 更虚拟一些,在算力、数据和模型三部分上,目前 Web2 商业化运作流程如下:
数据分为公共数据、公司自有数据和商业数据,需要专业的标注等预处理环节才能使用,比如 Scale AI 公司就为目前主流 AI 公司提供数据预处理;
算力分为自建和云算力租赁两种模式,GPU 硬件目前英伟达一家独大,CUDA 库老黄也准备很多年,目前软硬件生态一家独大,其次是云服务厂商的算力租赁,比如微软的 Azure、谷歌云和 AWS 等,很多提供一站式的算力和模型部署功能;
模型可以分为框架和算法两类,模型之战已经终结,谷歌的 TensorFlow 先来先凉,Meta 的 PyTorch 后发先至,但是不论是提出 TransFomer 的谷歌还是坐拥 PyTorch 的 Meta 都逐渐在商业化上落伍于 OpenAI,但是实力依旧不容小觑;算法目前 Transformer 一家独大,各类大模型主要在数据源和细节上开卷。
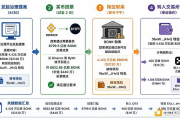
 AI 运作过程
AI 运作过程如前所述,AI 应用领域广泛,比如 Vitalik 所说的代码修正早已经投入使用,如果换个视角,Crypto 能为 AI 做的主要集中在非技术领域,比如去中心化的数据市场、去中心化的算力平台等等,去中心化的 LLM 有一些实践,但是要注意,用 AI 分析 Crypto 代码和区块链上大规模跑 AI 模型根本不是一回事,以及在 AI 模型中加一些 Crypto 因素也很难称得上是完美结合。
Crypro 目前还是更擅长生产和激励,异想天开用 Crypto 强行改变 AI 的生产范式则大可不必,这属于为赋新词强说愁,拿着锤子找钉子,Crypto 融入 AI 的工作流以及 AI 赋能 Crypto 才是合理选择,以下是我总结的比较可能的结合点:
去中心化的数据生产,比如 DePIN 的数据采集,以及链上数据的开放性,蕴藏着交易数据的富矿,可用于金融分析、安全分析和训练数据;
去中心化的预处理平台,传统预训练并无不可攀越的技术壁垒,而在欧美大模型的背后,是第三世界人工标注员的高强度劳动;
去中心化的算力平台,个人带宽、GPU 算力等软硬件资源的去中心化激励和使用;
zkML,传统的数据脱敏等隐私手段并不能完美解决问题,zkML 可以隐藏数据指向性,也可以有效评估开源和闭源模型的真实性和有效性;
这四个角度是我能想到的 Crypto 能为 AI 赋能的场景,AI 是通用工具,AI For Crypto 的领域和项目就不再赘述,大家可以自行研究。
可以发现,Crypto 目前主要在加密、隐私保护和经济学设计上发挥作用,技术结合点只有 zkML 有一些尝试,这里可以开一下脑洞,如果未来 Solana TPS 真能跑到 10 万+,Filecoin 和 Solana 结合又比较完美的话,能不能打造一个链上 LLM 环境,这样能打造出一个真实的链上 AI,改变目前的 Crypto 附着于 AI,两者地位不对等的关系呢?
无需多言,英伟达 RTX 4090 显卡是硬通货,目前的某个东方大国很难获得,但是更严重的是,个人、小公司和学术机构也遭遇了显卡危机,毕竟大型商业公司才是氪金玩家,如果能在自购、云厂商之外开辟第三条道路,很明显具备实际的商业价值,也就脱离了纯粹的炒作,合理的逻辑应该是“如果不用 Web3,则无法维持项目运作”,这种才是 Web3 For AI 的正确姿势。
 Web3 视角下的 AI 工作流
Web3 视角下的 AI 工作流数据之源:Grass 和 DePIN 汽车全家桶
Grass 由 Wynd Network 推出,Wynd Network是一个闲置带宽售卖市场,Grass 是一个开放式的网络数据获取和分发渠道,不同于单纯的数据收集和售卖,Grass 具备将数据清洗和验证功能,以规避越来越封闭的网络环境,不仅如此,Grass 希望能直接对接上 AI 模型,为其提供直接可用的数据集,AI 的数据集需要专业处理,比如大量的人工微调,以满足 AI 模型的特殊需求。
扩展一下,Grass 要解决数据售卖的问题,而 Web3 的 DePIN 领域能生产 AI 需要的数据,主要集中在汽车的自动驾驶上,传统上的自动驾驶需要对应公司自行积累数据,而 DIMO、Hivemapper 等项目直接运行在汽车之上,采集越来越多的汽车驾驶信息和道路数据。
在以往的自动驾驶中,需要汽车识别技术和高精地图两部分,而高精地图等信息被四维图新等公司长期积累,形成事实上的行业壁垒,如果后来者借助 Web3 数据反而具备弯道超车的机会。
数据预处理:解放被 AI 奴役的人类
人工智能可以分成人工标注和智能算法两部分,第三世界,如肯尼亚和菲律宾等地区负责人工标注等价值曲线最低的部分,而欧美的 AI 预处理公司拿走大头收入,进而出售给 AI 研发企业。
随着 AI 的发展,更多的企业盯上这部分业务,在竞争下数据标注的单价越来越低,该部分业务主要就是给数据打标签,类似识别验证码的工作,并无技术门槛,甚至有 0.01 元人民币的超低价。
 图源:https://aim.baidu.com/product/0793f1f1-f1cb-4f9f-b3a7-ef31335bd7f0
图源:https://aim.baidu.com/product/0793f1f1-f1cb-4f9f-b3a7-ef31335bd7f0在这种情况下,诸如 Public AI 等 Web3 数据标注平台也具备实际商业市场,链接 AI 企业和数据标注民工,使用激励体系取代单纯的商业低价竞争模式,但是要注意,Scale AI 等成熟企业的标注技术保证可靠的质量,而去中心化的数据标注平台如何控制质量,禁止撸毛党则是绝对刚需,本质上这是 C2B2B 的企业服务,单纯的数据规模和数量并不能说服企业。
硬件自由:Render Network 和 Bittensor
需要说明,跟比特币矿机不同,目前没有专用的 Web3 AI 硬件,现存的算力、计算平台都是成熟硬件叠加 Crypto 激励层改造而来,本质上可以归纳为 DePIN 领域,但是和数据来源项目有所区别,故按照 AI 工作流写在此处。
Render Network 是“老项目”,并不完全为 AI 准备,最早致力于渲染工作,一如 Render 之名,2017 年开始运营,当时的 GPU 还没那么疯狂,但是市场机遇已经逐步出现,GPU 显卡市场,尤其是高端显卡被英伟达垄断,高昂的价格阻碍渲染、AI 和元宇宙使用者的进入,如果能在需求方和供给方构建起通道,那么类似共享单车的经济模型就有机会成立。
并且 GPU 资源并不需要实际交接硬件,仅调配软件资源即可,更值得一提的是,Render Network 在2023 年便转投 Solana生态,舍弃 Polygon,在 Solana 并未回暖之时的投奔也被时间证明是正确之举,对于 GPU 使用和分配而言,高速网络是一种刚需。
如果说 Render Network 是老项目,那么 Bittensor 则风头正盛。
BitTensor 建构在波卡之上,其目标是通过经济激励训练 AI 模型,比拼各节点能否将 AI 模型训练至误差最小或者效率最高,也是较为符合经典的 AI 上链流程的 Crypto 项目,但是真正的训练过程依然需要英伟达 GPU 和传统平台,整体上类似 Kaggle 等竞赛平台。
zkML 和 UBI:Worldcoin 的 AB 面
零知识机器学习(zkML)通过将 zk 技术引入 AI 模型训练过程,以此来解决数据泄露、隐私失效和模型验真的问题,前两者容易理解,zk 加密后的数据仍然可以被训练,但是不会再泄露个人或者隐私数据。
模型验真是指某些闭源模型的评估问题,在 zk 技术加持下,可以设定某个目标值,那么闭源模型可以通过验证结果的方式证明自己的能力,而无需公开计算过程。
Worldcoin 不仅是较早设想 zkML 的主流项目,还是 UBI(人类基本收入)的拥趸,在其设想中,未来 AI 的生产力将远超人类的需求上限,因此真正的问题在于公平分配 AI 的福利,UBI 的理念将通过 $WLD 代币像全球用户分享,因此必须进行实人生物识别,以遵循公平原则。
当然,目前的 zkML 和 UBI 还在早期实验阶段,但是足够有趣,我会持续关注。
AI 的发展,以 Transformer 和 LLM 为代表的路线发展也会逐渐陷入瓶颈,一如线性回归和神经网络,毕竟不可能无限制增加模型参数或者数据量,继续增加的边际收益会递减。
AI 也许是涌现出智慧的种子选手,但现在幻觉问题十分严重,其实可以看出,目前认为 Crypto 能改变 AI 的幻觉是一种自信,同时也是一种标准的幻觉,Crypto 的加入很难从技术上解决幻觉问题,但至少可以从公平、透明角度入手改变一些现状。
参考文献:
OpenAI: “GPT-4 Technical Report”, 2023; arXiv:2303.08774.
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin: “Attention Is All You Need”, 2017; arXiv:1706.03762.
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, Dario Amodei: “Scaling Laws for Neural Language Models”, 2020; arXiv:2001.08361.
Hao Liu, Wilson Yan, Matei Zaharia, Pieter Abbeel: “World Model on Million-Length Video And Language With RingAttention”, 2024; arXiv:2402.08268.
Max Roser (2022) - “The brief history of artificial intelligence: The world has changed fast – what might be next?” Published online at OurWorldInData.org. Retrieved from: 'https://ourworldindata.org/brief-history-of-ai' [Online Resource]
An introduction to zero-knowledge machine learning (ZKML)
Understanding the Intersection of Crypto and AI
Grass is the Data Layer of AI
Bittensor: A Peer-to-Peer Intelligence Market
 喜来顺财经
喜来顺财经