作者:郝天;来源:链上观

最近,NEAR founder @ilblackdragon 将亮相英伟达AI大会的消息,让NEAR公链赚足了眼球,市场价格走势也喜人。不少朋友疑惑,NEAR链不是All in在做链抽象么,怎么莫名其妙就成了AI头部公链了?接下来,分享下我的观察,顺带科普下一些AI模型训练知识:
1)NEAR创始人Illia Polosukhin有过较长时间的AI背景,是Transformer架构的共同构建者。而Transformer架构是如今LLMs大型语言模型训练ChatGPT的基础架构,足以证明NEAR老板在成立NEAR前确实有AI大模型系统的创建和领导经验。
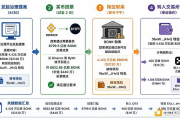
2)NRAR 曾在NEARCON 2023上推出过NEAR Tasks,目标是为了进行人工智能模型的的训练和改进,简单来说,模型训练需求方(Vendor)可以在平台发布任务请求,并上传基础数据素材,用户(Tasker)可以参与进行任务答题,为数据进行文本标注和图像识别等人工操作。任务完成后,平台会给用户NEAR代币奖励,而这些经过人工标注的数据会被用于训练相应的AI模型。
比如:AI模型需要提高识别图片中物体的能力,Vendor可以将大量图片中带有不同物体的原始图片上传到Tasks平台,然后用户手动标注图片上上物体位置,就可以生成大量“图片-物体位置”的数据,AI就可以用这些数据来自主学习来提高图片识别能力。
乍一听,NEAR Tasks不就是想社会化人工工程来为AI模型做基础服务嘛,真有那么重要?在此加一点关于AI模型的科普知识。
通常情况下,一次完整的AI模型训练,包括数据采集、数据预处理和标注、模型设计与训练、模型调优、微调、模型验证测试、模型部署、模型监控与更新等等过程,其中数据标注和预处理为人工部分,而模型训练与优化为机器部分。
显然,大部分人理解中的机器部分要明显大于人工部分,毕竟显得更高科技一些,但实际情况下,人工标注在整个模型训练中至关重要。
人工标注可以为图像中的对象(人、地点、事物)等添加标签,供计算机提升视觉模型学习;人工标注还能将语音中的内容转化为文本,并标注特定音节、单词短语等帮助计算机进行语音识别模型训练;人工标注还可以给文本添加一些快乐、悲伤、愤怒等情感标签,让人工智能增强情感分析技能等等。
不难看出,人工标注是机器开展深度学习模型的基础,没有高质量的标注数据,模型就无法高效学习,如果标注数据量不够大,模型性能也会受到限制。
目前,AI微创领域有很多基于ChatGPT大模型进行二次微调或专项训练的垂直方向,本质上都是在OpenAI的数据基础上,额外增加新的数据源尤其是人工标注数据来施展模型训练。
比如,医疗公司想基于医学影像AI做模型训练,为医院提供一套在线AI问诊服务,只需要将大量的原始医学影像数据上传到Task平台,然后让用户去标注并完成任务,就产生了人工标注数据,再将这些数据对ChatGPT大模型进行微调和优化,就会让这个通用AI工具变成垂直领域的专家。
不过,NEAR仅仅凭借Tasks平台,就想成为AI 公链龙头显然还不够,NEAR其实还在生态系统中进行AI Agent服务,用来自动执行用户一切链上行为和操作,用户只需授权就可以自由在市场中买卖资产。这有点类似Intent-centric,用AI自动化执行来提升用户链上交互体验。除此之外,NEAR强大的DA能力可以让它在AI数据来源的可追溯性上发挥作用,追踪AI模型训练数据有效性和真实性。
总之,背靠高性能的链功能,NEAR做AI方向的技术延展和叙事引导,似乎要比纯链抽象要不明觉厉多了。
半个月前我在分析NRAR链抽象时,就看到了NEAR链性能+团队超强web2资源整合能力的优势,万万没想到,链抽象还没有普及开来摘到果子,这一波AI赋能再一次把想象力放大了。
Note:长期关注还是得看NEAR在“链抽象”上的布局和产品推进,AI会是个不错的加分项和牛市催化剂!
 喜来顺财经
喜来顺财经