作者:Crazyox;来源:X,@crazyox
在过去三年的生成式 AI 狂热中,全球科技界陷入了一种由 GPU 供给率和算力浮点数(FLOPS)构成的“算力叙事垄断”。
所有人都在盯着 NVIDIA 的发布会,将 H100、B200 以及未来的 Rubin 视为通往 AGI 的唯一圣杯。
然而,一个极其危险的行业认知偏差正在发生:市场误将“计算的速度”当成了“智能的全部”。
当大语言模型(LLM)从单纯的“无状态问答(Stateless QA)”演进为具备长程规划、工具调用和自主决策能力的“有状态智能体(Stateful Agent)”时,硬件底层的权力重心正在发生一场结构性移转。
Agentic AI 的核心瓶颈与终极壁垒,从来不是算力,而是记忆。
这不仅是一场软件应用层的范式迁移,更是一场对整个 IT 基础设施硬件层级的颠覆性清洗。
存储,正在从计算的“冷家电”,跃升为智能的“中枢神经”。
从第一性原理(First Principles)出发,人类乃至宇宙中一切形式的“智能”,其终极追求只有两件事:无限的计算能力(脑子转得快)与无限的存储能力(记性足够好)。
在物理世界中,计算本质上是能量对空间的改变速度(时钟频率、吞吐量),而存储则是能量在时间维度上的留存状态(熵减的维持)。
在人类社会中,评价一个人的智力水平,我们看重的是“博闻强识”与“反应敏锐”的统一。
没有博闻强识的底座,反应敏锐只是无源之水。
机器智能正在严丝合缝地沿着这条路径演进。
但在当前的冯·诺依曼架构下,计算与存储之间存在着一道致命的“存储墙(Memory Wall)”。
随着 Agentic AI 的到来,传统的中央处理器(CPU)角色已经被完全边缘化。它早就不再承担核心的计算逻辑,而是退化为一个“协理员”。
新型的智能硬件层级正在按照对“智能的贡献度”重新洗牌:

在这个新秩序中,存储(Memory)被推到了绝对的第一优先级。
因为算力决定了智能体思考的单点爆发力,而存储的容量与带宽,决定了智能体认知的边界、深度以及生命周期的长度。
市场目前对存储的理解,大多停留在 HBM(High Bandwidth Memory)的短缺和英伟达显存的高昂造价上。
但这只是冰山露在海面上的尖角。
从技术底层来看,大模型的推理过程分为两个截然不同的阶段:Prefill(预填充阶段) 和 Decode(解码逐字生成阶段)。
Prefill 阶段是 Compute-bound(计算受限)的,它需要大吞吐量的 GPU 算力来一次性处理输入的 Prompt。
Decode 阶段则是典型的 Memory-bound(内存带宽受限)任务。
大模型每生成一个 Token(一个字或词),都需要将整套模型的权重(Weights)以及之前所有对话产生的 KV Cache(键值缓存) 从显存里完整地“搬运”一遍。

这导致了一个极其荒谬的现象:计算核心(Tensor Core)大部分时间都在“空转”等待数据的送达。
带宽不够,再高昂、再先进的 GPU 也不过是摆设。
这就是为什么 NVIDIA 每一代芯片的升级,算力增长往往是线性的,而 HBM 的带宽和容量增长却是指数级的。
HBM 的本质,是高昂的显存堆叠技术为了苟延残喘地追赶计算核心速度,而妥协出的“肉搏式”硬件方案。
但这只是市场已经讲烂了的故事,更深处的范式革命,发生在 GPU 集群之外。
我们天天听各大模型厂商兜售“100万、200万甚至无限的上下文窗口(Context Window)”。
普通投资者和非技术背景的行业观察者普遍认为,这些长上下文是在动辄数万张 GPU 组成的 AI 算力集群中被实时拼凑和处理的。
这是一个巨大的行业误解。
GPU 阵列的显存极其昂贵且空间有限,它只负责最核心的“矩阵乘法”矩阵计算。
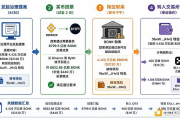
那高达 1M 甚至数兆的超长上下文,其真正的物理组装地点、清洗工坊与状态维持网络,是在跑 Agentic 系统的传统通用服务器里(由 CPU + 超大 DRAM 构成)。
当我们拆解一个全自动的 Agentic 智能体系统时,这些传统服务器的 DRAM(动态内存)里正在发生着一场不为人知的数据风暴:
1. 动态状态机(Dynamic State Machine)的实时维持
Agent 不是单次触发的问答机器人,它是一个持续运行的“状态机”。
它需要实时将用户的长期记忆(基于向量数据库的冷数据,从 NAND 唤醒)、短期记忆(当前对话的上下文,热数据)源源不断地加载到 DRAM 中。
2. 系统规范(System Prompts)与元认知(Meta-Cognition)的注入
一个复杂的 Agent 往往包含数十个不同角色的子智能体(Sub-agents)。
每个子智能体都有长达数万字的系统行为规范、防御提示词、合规边界。
这些元认知数据必须常驻内存,以便随时被主系统调用。
3. 工具链与技能库(Skills & Tools Descriptions)的编排
Agent 在执行任务时(如“帮我分析过去三年的财报并生成图表”),需要调用无数的外部 API、Python 解释器或 SQL 数据库。
这些工具的参数格式、调用逻辑、中间执行状态,全部积压在内存中。
4. 极端上下文的“内存压缩与蒸馏”
当交互轮次让 Token 数冲向 1M 的极限时,Agent 系统不能直接把这 1M 数据扔给 GPU(会导致显存溢出或延迟爆炸)。
Agentic 服务器必须在 DRAM 中利用算法对上下文进行动态的注意力蒸馏(Attention Distillation)、语义剪枝(Semantic Pruning) 和 实时总结(Real-time Summarization)。
这一系列复杂的、高频的、带有强逻辑判断的数据流转,100% 跑在 Agentic 服务器的 DRAM 里。
GPU 只是那个负责在最后关头“提笔写字”的流水线工人,而传统服务器里由超大 DRAM 构成的空间,才是运筹帷幄的“幕僚团”和“档案馆”。
为了理解这场存储革命的恐怖体量,我们必须将其与过去的互联网/移动互联网时代进行纵向对比。
在过去的 Web 2.0 时代(无论是谷歌的搜索、抖音的推荐,还是淘宝的广告系统),核心逻辑是“无状态的短文本交互”。
你点击一个视频,系统向服务器发送一个几 KB 的请求(Request),服务器返回一个推荐列表(Response)。
互联网服务器几乎不需要处理和维持用户的实时上下文。
数据中心只需要在后台数据库里留存非常稀疏的用户标签(如:男性、25岁、喜欢数码)。这个数据量极其微小。
Agentic 系统处理的数据量,是传统互联网系统的 20 倍,甚至 100 倍以上。
因为 Agent 处理的是“全意识流(Full Stream of Consciousness)”。
当你在和一个个人的 AI Agent 协同工作时,它不仅要记住你刚刚说的那句话,还要实时调用你整个操作系统的文件、你的日程表、你过去一年的邮件往来,甚至你的语气偏好。
每一次 Agent 的思考流(Thought Stream),都是一次多源数据的空间交汇。这种对内存空间的强占有性,是人类 IT 史上从未出现过的“吞噬怪”。
华尔街和分析师们喜欢听宏大的故事,但工业界的供应链从来不撒谎,它们用真金白银的设备采购指标投出了选票。
在传统的云计算数据中心里,一台通用服务器的配置比例(CPU 核心数与内存容量的配比)长期维持在:
$$\text{1 CPU Core} : \text{4 GB DRAM}$$
这是一个维持了十几年、被认为最符合经济效益的黄金比例。
然而,过去一年的供应链订单显示,为了适配 Agentic AI 系统的全量铺开,这个比例已经发生了结构性断裂,直接跃升至:
$$\text{1 CPU Core} : \text{16 GB DRAM}$$
并且,这个数字正在向 1 : 32 甚至 1 : 64 狂飙。
但这仅仅是硬件配比的单点变化,真正的链式反应发生在并发服务能力(Concurrency Capacity) 的塌陷上。
在 Agentic 状态下,因为单个用户所占用的上下文、记忆体和工具链数据过于庞大,单颗 CPU 能够同时服务的用户数(QPS),暴跌到传统互联网时代的几分之一甚至十几分之一。
这是一个惊人的商业算力黑洞。
这意味着,当整个全球 IT 基础设施彻底从 Web 2.0 切换到 Agentic AI 驱动的生态时,我们要维持和过去一样的用户并发量,全球数据中心所需的硬件总量将发生异变:
CPU 数量: 并非如市场所说的被 GPU 完全取代,而是作为存储调度器,其数量将迎来几倍至十几倍的反弹增长。
DRAM(内存)总量: 将迎来几十倍乃至上百倍的指数级需求暴增。
当全行业都在用“存储芯片是周期行业(Cyclical Industry)”的传统眼光来审视三星、SK 海力士和美光的财务报表时,他们正在犯下时代的错误。
拉长时间轴看,万物皆有周期。
但当技术范式发生跃迁时,新需求的爆发会彻底拉长周期的波峰,将一个原本 2 年一震荡的“短库存周期”,硬生生撑成一个长达数十年、震耳欲聋的“超级结构性周期(Super Structural Cycle)”。
当前的时间节点具备两个极端的剪刀差特征:
人群渗透率极低: 全球真正用上原生 Agent 系统的活跃用户,比例甚至不足 1%。
使用深度极浅: 绝大多数用户对 AI 的使用还停留在“帮我润色一段话”的 Stateless 阶段,真正让 Agent 7x24 小时挂机搞定复杂工作流的深度应用才刚刚抬头。
在未来至少 5 年内,我们根本看不到这一轮由 Agentic AI 驱动的存储需求周期的顶部。
软件范式的改变(从无状态问答到长程有状态智能体),必然逼迫硬件范式发生同频共振(从计算中心论走向存储中心论)。
谁真正读懂了 AI 智能体的底层运行逻辑,谁就会明白:这一轮的存储暴涨,不是硅周期的回暖,而是一次人类信息技术架构的推倒重来。
算力决定了 AI 能跑多快,但存储,最终决定了 AI 能走多远。
 喜来顺财经
喜来顺财经